Definition:
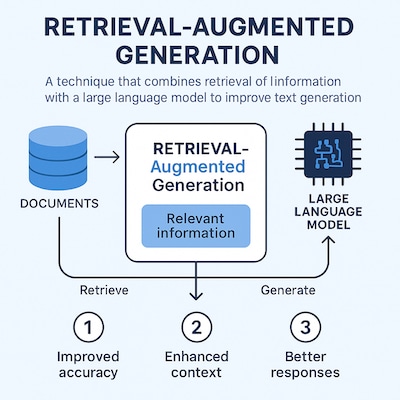
Retrieval-Augmented Generation (RAG) ist ein KI-Modell-Architektur-Ansatz, bei dem ein generatives Sprachmodell (z. B. GPT oder BERT) mit einem externen Informationsabrufsystem (Retriever) kombiniert wird. Ziel ist es, aktuelle, kontextrelevante und faktisch korrekte Texte zu generieren, auch wenn die zugrundeliegende Modellarchitektur nicht über diese Fakten verfügt.
Statt sich allein auf im Modell gespeicherte Informationen zu verlassen, sucht RAG bei jeder Anfrage gezielt nach externen Informationen (z. B. in Dokumenten, Datenbanken oder Wissensgraphen), um diese in die Antwortgenerierung einzubeziehen.
Wie funktioniert RAG?
Der RAG-Ansatz besteht aus zwei zentralen Komponenten:
1. Retriever
Ein Modul, das relevante Informationen aus einer großen Datenbasis (z. B. Wikipedia, interne Dokumente, FAQs) sucht und filtert. Typischerweise basierend auf Vektorsuche / semantischer Ähnlichkeit mit Embeddings.
2. Generator
Ein generatives Sprachmodell (z. B. T5, GPT), das basierend auf der Suchanfrage und den abgerufenen Textfragmenten eine natürlichsprachliche Antwort erzeugt.
Ablauf:
-
Nutzer stellt eine Anfrage („Wie funktioniert RAG?“)
-
Der Retriever durchsucht ein Dokumenten-Index nach passenden Textstücken
-
Diese Texte werden zusammen mit der Originalfrage an den Generator übergeben
-
Der Generator erstellt eine Antwort, die auf den abgerufenen Inhalten basiert
Beispielhafte Anwendung
Frage: „Wie funktioniert Blockchain bei Lieferketten?“
→ RAG-Modell durchsucht relevante Artikel und interne Whitepaper
→ Antwort wird erstellt, die konkrete Vorteile im Kontext der Lieferkette erklärt – auch wenn das Modell dieses Wissen vorher nicht besaß
Vorteile von Retrieval-Augmented Generation
✔ Aktualität
Informationen stammen aus dynamischen Datenquellen, nicht nur aus Trainingsdaten.
✔ Faktenbasierung
Antworten sind fundierter, da sie auf überprüfbaren Quellen basieren.
✔ Skalierbarkeit & Individualisierung
RAG kann an unternehmensinterne Datenquellen angepasst werden (z. B. Helpdesks, Wissensdatenbanken).
✔ Speicher-Effizienz
Externe Wissensbasis → weniger Notwendigkeit, alle Fakten ins Modell zu „trainieren“.
✔ Transparenz
Die genutzten Quellen können mitgeliefert werden („Grounded Answers“).
Typische Einsatzgebiete
-
Enterprise Chatbots (z. B. mit Zugriff auf interne Dokumente)
-
Wissenschaftliches Recherchieren (z. B. aus Papers oder Fachliteratur)
-
Kundensupport-Automatisierung (FAQs + individuelle Vertragsdaten)
-
Code-Dokumentation & API-Hilfen
-
Gesundheitsinformationen basierend auf verifizierten Quellen
Technologien & Frameworks
| Komponente | Tools / Technologien |
|---|---|
| Retriever | ElasticSearch, FAISS, Pinecone, Weaviate |
| Embedding Modelle | Sentence Transformers, OpenAI Embeddings, Cohere |
| Generator | T5, BART, GPT-3/4, FLAN-T5 |
| Frameworks | LangChain, Haystack, LlamaIndex, HuggingFace Transformers |
Viele Open-Source-Projekte bieten bereits fertige Pipelines für RAG-Workflows an.
Unterschied zu klassischen LLMs
| Kriterium | Klassisches LLM | RAG-Modell |
|---|---|---|
| Datenbasis | Nur das Training | Externe Quellen (retrieved) |
| Aktualität | Begrenztes Wissen | Dynamisch durch Abruf |
| Fehlerrate (Halluzinationen) | Höher | Reduziert |
| Individualisierbarkeit | schwierig | hoch |
| Transparenz | Gering | Quellennachweis möglich |
Herausforderungen & Limitationen
-
Retrieval-Qualität ist entscheidend – schlechte Suchergebnisse → schlechte Antworten
-
Kontextfenster begrenzt – zu viele Dokumente können nicht gleichzeitig verarbeitet werden
-
Verzögerung durch Abfrageprozess – Latenz kann steigen
-
Fehlende Evaluation – Was ist „richtig“? Nicht jede Antwort lässt sich objektiv bewerten
-
Skalierung & Kosten – bei großen Dokumentenpools teuer in Infrastruktur
Fazit
Retrieval-Augmented Generation (RAG) verbindet das Beste aus zwei Welten: Die Flexibilität und Sprachkompetenz generativer KI mit der Zuverlässigkeit und Aktualität strukturierter Wissensquellen. Der Ansatz ist ideal für Anwendungen, die verlässliche, dynamische und kontextbezogene Informationen benötigen – z. B. Chatbots, Wissensassistenten oder redaktionelle Systeme.
RAG ist nicht nur ein cleverer Workaround für veraltete Trainingsdaten – es ist ein Zukunftsmodell für KI-Systeme, die mit echtem Wissen arbeiten sollen.
Retrieval-Augmented Generation (RAG) – Hybride Intelligenz für bessere Antworten




